
Aggregate Windows Logs Natively
March 20, 2018Among most of our customers, the most common task consist of aggregation of logs and Microsoft Windows. In the past, our company has been using WinLogBeat, a third party service built by Elastic. Winlogbeats is installed and configured on each individual computer where logs are needed to be forwarded. An issue arises when the config, which controls which logs to forward or filter, needs to be updated or changed. While a service such as Chef is ideal for this problem, I haven't learned Chef to its fullest - yet.
This week I was given the pleasure of doing some research into forwarding logs from one Windows machine to another. During my search I stumbled upon Windows Event Forwarder (WEF) and Windows Event Collector (WEC), where together they accomplish this exact task and natively too. In addition, if their exists an Active Directory machine in the domain, it makes setting up the WEF for all client computers even simpler. Using Active Directory, a configuration can be created and trickled down to all client computers in the domain. In that configuration, a WEC server is defined which is used to store all the logs for either forwarding onto another service, or simply just used as a log backup. For those with a security concern, not that when a computer is first contacting the WEC host, it first verifies its identity on the domain, then all subsequent communication is handled by kerberos authentication (by default).
This Friday I plan on showing my findings to the team and the ease of use that Microsoft has actually made this ability. For a simple tutorial for setting up either WEF or WEC, see my Github Gist here.

NiFi is Awesome
Feb 27, 2018Apache NiFi is a software project from the Apache Software Foundation designed to automate the flow of data between software systems. Based on the "NiagaraFiles" software previously developed by the NSA and open-sourced as a part of its technology transfer program in 2014. [1] The software allows for quickly and easily setting up data flow pipelines to various services.
At Champion Technology Inc., NiFi allows us to test and develop various different data streams and move data around. NiFi allows the user to track the data flow from source to destination with a visual representation and statistics at every connection and process along the way. On top of being able to move data around, NiFi itself can be used to filter data to various different pipes and different forms of output. Having a Python background, being able to use Jython, a Java variant of Python, made creating steps that altered, omitted, or remove data a breeze.
Being able to quickly observe where data is going in a simple UI, and having scalability and stability of such a system is a major plus. When data seems to stop flowing it is nice to have the ability to quickly standup an intermediate system that can handle the data load and make debugging a complex system that much easier, AND it's free to use - why wouldn't you use NiFi? For more information on Nifi head to their homepage here.

Kafka
Feb 22, 2018Apache Kafka is an open-source stream-processing software platform developed by the Apache Software Foundation written in Scala and Java. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds. While our ELK stack has been working wonderfully, we have noticed that after a large inflow of data into our system, somewhere around 15mbps+ of data flowing through the STOMP output-plugin was causing issues. Mainly events were getting to our software slower and slower over time. Hopefully this issue will be resolved soon.
In the meantime, we chose to disable our use of the STOMP output-plugin and switched over to using the Kafka output plugin. Similar in use, Kafka is another great software that is now managed by the Apache foundation. Kafka is meant for building real-time streaming data pipelines that reliably get data between systems or applications and real-time streaming applications that transform or react to the streams of data. Topics in Kafka are always multi-subscriber; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it - exactly what we needed to replace STOMP.
The next step beyond Kafka is working with Elastic to determine the shortcomings of their stomp output plugin and why it is having such speed issues. If the previous posts haven't made it obvious enough, having flexibility in solutions and implementation is important to our software as our customers can have any array of these services to accomplish the necessary steps to get the appropriate data to our software.

ELK & AMQ Bundled with the Power of Docker
Feb 12, 2018This week I got the pleasure to merge my knowledge of Docker Compose and the ELK stack with AMQ. As from my previous posts, Docker Compose allows to easily create some small simple configuration files to automate the Docker process of initializing, starting, and stopping of Docker containers. While ELK (Elasticsearch, Logstash, and Kibana) handles moving, filter, displaying, and searching abilities of logs. Apache AMQ makes piping the data to specific locations such as a specific topic or queue simple. Bundling these services together just seemed like the obvious next move.
This week it actually showed more practical use than simply researching into the topic. A client needed services that they were unfamiliar with, all hosted on the Amazon Cloud (AWS) a flavor of linux that is - different. Luckily the client was familiar with Docker and its purpose, we were able to quickly bundle up some simple configurations with a Docker Compose file and set it on its way. Quickly and reliably assembling the necessary services for someone who was completely unfamiliar with either services. In addition, the simple .yaml file that Docker Compose uses, they learned what and where the service configuration files lived and could alter them to their needs.
Having this ability makes debugging out of our shared development environment and into a single local environment as simple as typing in a single command, and quickly showed us the power of Docker when needed by a client. This single command starts ELK, AMQ, and connects everything needed by them to function properly. The process was relatively simple, and you can view the entire project at this Github repository.

Docker Compose
Feb 6, 2018Docker Compose is a tool for defining and running multi-container Docker applications. A single Dockerfile is used to define any given Docker Container, while Docker Compose has its own configuration file that helps define how the multiple containers interact with one another. For instance, for communication between containers their needs to be a network backend that defines which containers can communicate with one another. For an example Docker Compose file to follow along, see my docker-compose file here.
The previous docker-compose file is managing two services, both Logstash and AMQ. The `build` section specifies to look in that folder for the Dockerfile for assembling the container and use that, then I give that container a name. Since we can have multiple instances of the same container, Docker uses an internal DHCP IP addresses behind the seen, which is randomly mapped to the host machine. Thus, if a services is looking for another service on a specific port, they need to be changed in order to communicate. As seen from the ports section, I am simply specifying map this port to this port on the host machine, eg. container-port:host-port. I then specify which network the container should talk on, and you may have noticed that both services use the same network. Putting both services on the same network allows the services to communicate to each other even though they are both isolated in their own containers. Lastly, the volumes section allowed me to specify a folder from the container to actually be mapped to a folder on my host machine, giving me the ability to have persistent data across sessions - extremely useful.
Hopefully you can see now why Docker and Docker-Compose can be so powerful and useful for both development and production environments. To learn more about Docker-Compose, click here.
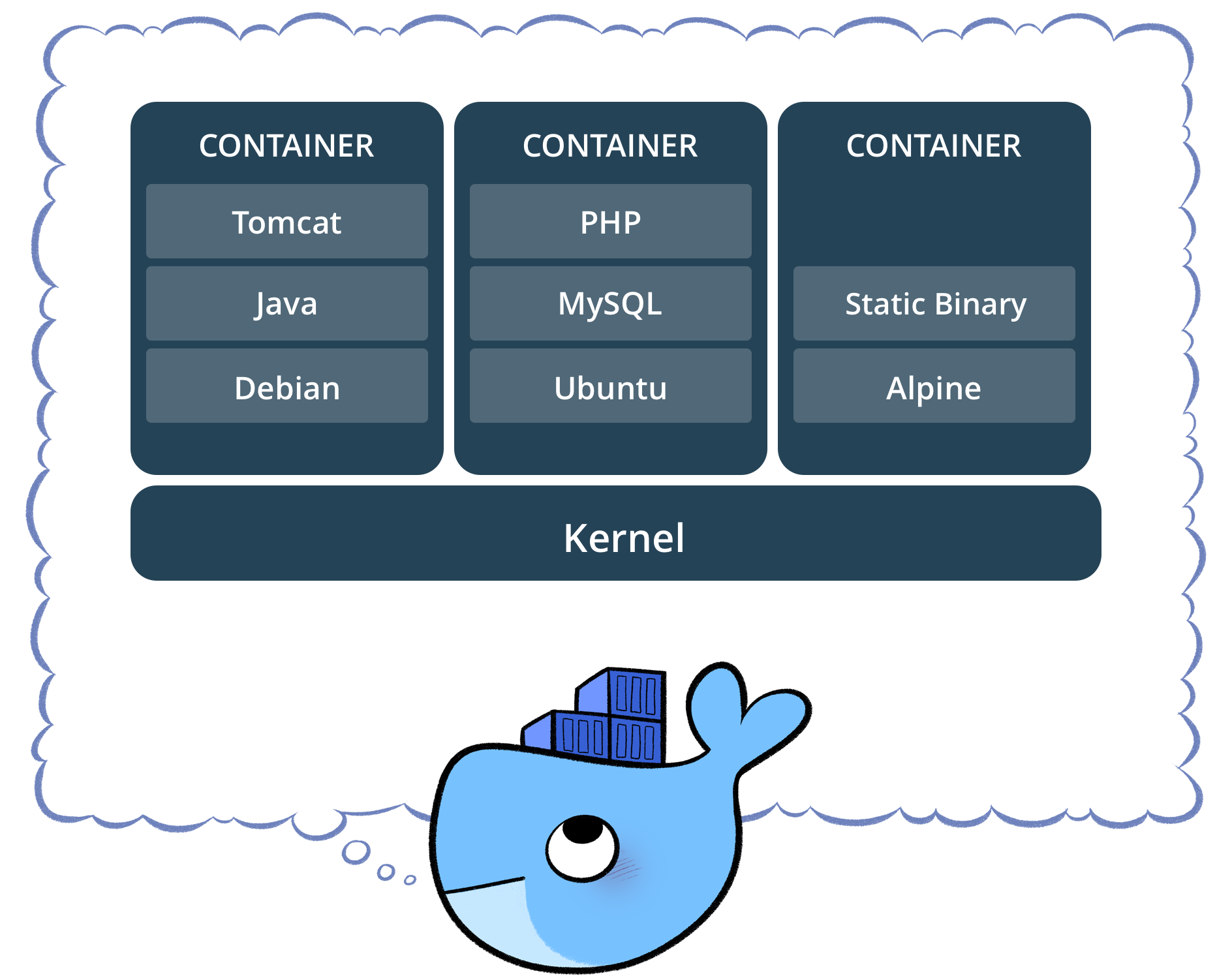
Docker Essentials
Jan 30, 2018Being able to consistently deploy essential infrastructure is crucial for showing a product to a client. Docker aids in this field as instead of having to setup a Virtual Machine (VM) for all services, using docker containers keeps deploying microservices a breeze.
Traditionally, setting up a service such as Apache's Active Message Queue (AMQ), a user would either need to download and run their service locally or setup a VM - going through the process of installing an OS, updating, and finally installing and configuring the service. This is where Docker comes into play. Instead of having individual VMs dedicated to an entire OS and the service, Docker splits the OS from service. This is accomplished by Docker creating a VM, a very minimal one at that (~5MB), and where things turn weird is the ability to share the kernel between Docker "Containers."
Think of a Container as any given service, for our example let's assume it's a Logstash instance. Traditionally, if we wanted to setup multiple Logstash instances, we would need to setup everything from the ground up from the OS level up. With Docker, we can simply create the base container for Logstash, "spin up" the necessary containers, and load the various config files that we'd like to test, where each is on one VM and all are sharing the kernel. At Champion, this proved useful since we needed to test various config files, cleanly shifting which Logstash we were pointing at and quickly seeing results of each.
While our use wasn't necessarily traditional, it proved useful for development purposes. The true power of Docker really shines when you can dynamically spin services up when needed and bring down others that are idling, creating much more flexible and scalable systems. To read me about Docker and its uses, click here.

Logging with Logstash
Jan 22, 2018Logstash is a tool for managing events and logs. When used generically the term encompasses a larger system of log collection, processing, storage and searching activities. Collection is accomplished via configurable input plugins including raw socket/packet communication, file tailing, and several message bus clients. Once an input plugin has collected data it can be processed by any number of filters which modify and annotate the event data. Finally logstash routes events to output plugins which can forward the events to a variety of external programs including Elasticsearch, local files and several message bus implementations.
DarkLight can consume raw data at a rapid pace, but at times it is easy to filter out false-positives using a simpler mechanism before data even gets to DarkLight. To accomplish this a log aggregator is needed. Using a log aggregator both simplifies where to send logs to when configuring multiple computers to send system logs, but also allows us to pipe the raw data around using one service.
An additional filter that was used in the process, similar to regex, was a Logstash plugin called grok. There are many times where unstructured data is sent along down the pipe. Extracting this data can be hard to do, and being consistent and reliable - even harder. Taking the time to learn grok, some of the built in patterns and sticking with the trusty grok debugger, we were able to gather, filter and provide structure to an otherwise structureless events.

Apache's ActiveMQ
Jan 17, 2018Apache's ActiveMQ is an open source message broker written in Java together with a full Java Message Service client. The communication is managed with features such as computer clustering and ability to use any database as a JMS persistence provider besides virtual memory, cache, and journal persistency. These features allow us to create queues and topics which provides us the ability to create pipelines of data from one service to another.
At Champion Technology this service provides us a means of moving data around where needed and create topics to allow multiple consumers to grab logs off of any given pipe. The flexibility of AMQ is excellent as it is easy to create virtual topics or queues, which is useful because sometimes it is necessary to filter out data using another service (for example filtering out a whitelisted server or user) but if for debug purposes we can easily point to another topic name that has the raw data.
Using Virtual Topics has been a God sent as being able to quickly change a config to allow additional queues or topics on the same machine allows for greater flexibility instead of having to standup another physical topic/queue altogether. Having this feature allowed us to maintain a queue with original raw data and another for testing different filter on a virtual Logstash instance that itself piped back to another virtual topic. To find out more about ActiveMQ and what it has to offer head over here!